
- Azure IaaS (1) – první VM z grafického portálu
- Azure IaaS (2) – první VM z PowerShell
- Azure IaaS (3) – první VM z Azure CLI
- Azure IaaS (4) – první VM z ARM šablony
- Azure IaaS (5) – Network security group
- Azure IaaS (6) – vlastní image
- Azure IaaS (7) – automatizace stavu VM při vytvoření
- Azure IaaS (8) – Availability Set aneb jak je to s SLA
Pro vaše virtuální servery dává Azure SLA 99,95. To nezní špatně, ale pozor. Nevztahuje se na konkrétní osamocenou VM, na tu nedostanete SLA vůbec žádné. Chceme-li SLA, musíme použít skupinu VM v Availability Setu. Jak na to? Co to znamená z aplikačního pohledu?
Availability Set vs. vaše aplikace
Azure negarantuje, že konkrétní VM bude mít nějakou dostupnost. SLA dostanete, pokud budete mít alespoň dvě VM v Availability Setu. To znamená, že 99,95% času alespoň jedna z těchto VM nerušeně poběží. Pokud vaše aplikace nejsou alespoň trochu zralé na cloud, nebudou výsledky dobré.
Možná máte nějaký stroj, který je docela důležitý, ale běží na jednom fyzickém systému či VM. Aplikace na něm je architekturou stará 10 či 20 let a aplikační redundanci vůbec nepodporuje. Dostupnost dost možná řešíte infrastrukturně. Možná používáte specializovaný high-end hardware, který je nesmírně spolehlivý a mnohé problémy dokáže izolovat a vyřešit sám, takže aplikace může nerušeně pokračovat dál. Možná na úrovni hypervisoru umíte nastartovat rychle VM jinde nebo si dokonce kopírujete stav paměti. Azure (a prakticky žádný public cloud) vám něco takového nenabídne. Používají ty nejlevnější servery a havárie konkrétního kusu a s tím spojená nedostupnost některých VM jsou prostě běžné. Pokud je vaše aplikace důležitá a opravdu ji nedokážete změnit na něco rozumnějšího, do cloudu nepatří.
Třeba vaše aplikace podporuje režim vysoké dostupnosti, možná nějaký cluster, takže nasazení v Availability Setu udělá co potřebujete. Ověřte ale, co takový failover pro vás znamená. V tuto chvíli možná provozujete aplikaci na nesmírně robustní infrastruktuře a failover se stane tak jednou za dva roky. Proto možná používáte scénář active/pasive, kdy druhá strana poměrně dlouho startuje a služba je výrazně ovlivněna, ale šetříte na licencích a snižujete složitost. Co se vám ale dělo jednou za dva roky na specializované infrastruktuře se vám v cloudu bude dít daleko častěji. Vezměte to v úvahu – možná bude z byznys hlediska rozumné změnit i váš HA model.
Ještě jedna věc je důležitá – aplikace se po startu musí umět vzpamatovat. Viděl jsem dost aplikací, které pokud restartujte server zůstanou v nějakém stavu čekání. Třeba nenajdou ostatní komponenty, vyžadují manuální vyčištění logu nebo startují více než jednu službu a nemají dořešené pořadí (něco nastartuje později, než se čekalo a tím se to nepovede).
Ideální jsou samozřejmě aplikace zrozené pro cloud, tedy cloud native. Ty mají typicky řadu bezestavových komponent, které lze libovolně zabíjet i rozmnožovat a mezi sebou se objevují automatizovanými prostředky, například s využitím cloud platformy či service discovery jako je Consul či Etcd. Stav aplikace je ukládán v datové vrstvě, kde se očekává redundantní a škálovatelný cluster (MySQL Percona, Redis cluster, Cassandra, MongoDB sharding a replikace, MS SQL) nebo je situace zjednodušena použitím PaaS platformy (Azure SQL, DocumentDB, Azure Table, Azure Redis).
99,95 a pokud ne, tak co?
Jak popíšu níže Azure vám dá SLA 99,95. Chtěl jsem ale zmínit, že ani to vás nemusí nijak spasit. Pokud jsem správně četl toto SLA se vztahuje na problémy, které měl Microsoft možnost ovlivnit. Při zemětřesení máte asi smůlu. Co dostanete, pokud SLA nebude dodrženo? Odškodnění byznys dopadů samosebou žádné a finančně půjde o 10% vaší měsíční útraty zpět ve formě kreditu (nebo 25% pokud bude dostupnost nižší, než 99%). Na nikom se tedy rozhodně nazahojíte!
Public cloud není o smlouvách a pokutách. Dostáváte detailní informace o tom jak cloud funguje a jakou dostupnost od jeho částí můžete očekávat. Je na vás zvážit rizika a implementovat aplikace a další prostředky tak, aby to vyhovovalo vašemu byznysu.
Jak funguje Availability Set
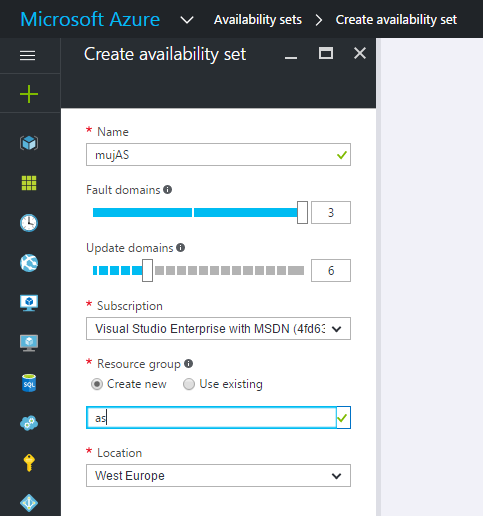
Začněme neplánovanými výpadky. Ve škále Azure (cca 600 000 fyzických serverů v každém regionu, kterých je už teď kolem třiceti) jsou selhání fyzického serveru či celého racku relativně časté. Azure pracuje s konceptem Fault Domain a v rámci Availability Setu máte dvě nebo tři v závislosti na nastavení. Pokud máte v tomto setu dvě VM, každé bude v jiné Fault Doméně, tedy minimálně v jiném racku (někdy i v jiném sále či dokonce budově, ale to přímo neovlivníte). Pravděpodobnost, že by neplánovaně selhaly obě VM je malá – tak malá, že vám Azure kvantifikuje tuto dostupnost jako 99,95.
V Azure vás čekají i plánované výpadky, tedy různé aktualizace a jiná údržba. Ve výchozím stavu má Availability Set 5 update domén, ale počet můžete zvýšit až na 20. Jde o množiny systémů, které se budou updatovat (= restartovat, způsobovat krátkou nedostupnost VM) společně. Pokud použijete 5 VM a 5 update domén, budou se restartovat postupně. Pokud máte 10 VM a 5 update domén, budou se restartovat po dvojicích.
Pokud máte klasickou třívrstvou aplikaci, dejte každou vrstvu do svého vlastního Availability Setu.
Availability Set nejsou data
Dnes se datům věnovat nebudeme, ale chtěl jsem poznamenat, že například blob storage (tam jsou disky vašich VM) má vlastní řešení dostupnosti. Totéž platí pro databázi jako služba, file share a další struktury. Tomu všemu se na cloudsvět ještě budeme věnovat.
Availability Set neřeší smrt regionu
Vše, co jsme dnes popsali, je vlastnost jednoho regionu – nejde o dostupnost mezi regiony. Teoreticky může vypadnou celý a s tím i kompletní Availability Set. Azure má prostředky jak řešit redundanci mezi regiony, ale zaměříme se na ně jindy. Traffic Manager dokáže dělat globální DNS balancing, backup a site recovery služby mohou replikovat datové disky, blob storage může být geo-replikována, DocumentDB i Azure SQL podporuje globální replikaci a tak dále. Sdílení aplikačního stavu mezi regiony vám může vyřešit třeba Service Bus nebo modernější Service Fabric.
Vyzkoušejte si
Dnes prozkoumáme jen Availability Set, což samo o sobě zas tolik neřeší. Ideální bude ho zkombinovat s Load Balancerem a to přesně uděláme příště.
Podívejte se v portálu jak založit Availability Set.
Můžete také použít PowerShell.
$as = New-AzureRmAvailabilitySet -ResourceGroupName test -Name as -Location westeurope
Pak už klasicky vytvářejte VM a jen ji přiřaďte do správného setu.
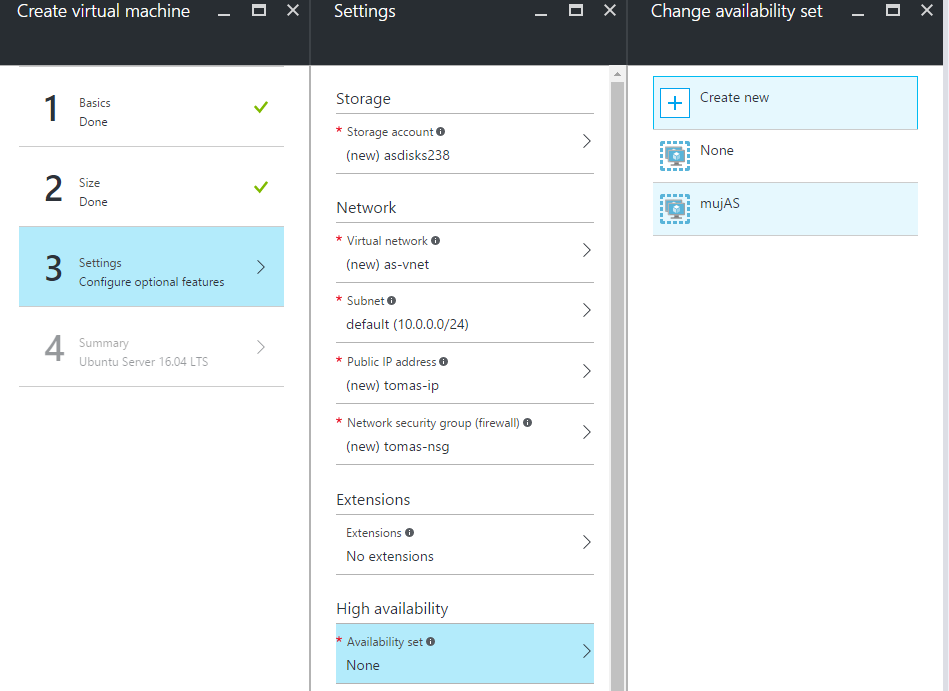
V PowerShell stačí přidat jedno přepínátko.
$vm01 = New-AzureRmVMConfig -VMName vm01 -VMSize "Standard_DS1_v2" -AvailabilitySetId $as.id
Dnes jsme si popsali Azure SLA pro compute a ukázali Availability Set. Je rozhodující znát jak Azure funguje a podle toho řešit způsob nasazení aplikací. Není to jen o compute, ale také o datech ve storage i databázi, geo-replikačních možnostech a globálnímu balancingu. O tom všem bude ještě řeč později. Příště ale uděláme jeden důležitý krok – webové servery v Availability Setu schováme za jednu veřejnou IP adresu Load Balanceru, který bude rozdělovat zátěž na naše nody. Současně bude monitorovat jejich dostupnost, takže případné restarty VM či jiné výpadky dokážeme překonat.
Chcete pomoci s návrhem on-premise řešení IaaS postaveným na Azure Pack/Stack, OpenStack nebo VMware? Potřebujete poradit s migrací aplikací a nasazením v Azure cloudu? HPE má certifikované Microsoft architekty a konzultanty a můžete také využít plně konvergovaných systémů pro vaše on-premise potřeby.
